Transbase
Crowd Queries
Version V8.4
Copyright © 2022 Transaction Software GmbH
ALL RIGHTS RESERVED.
While every precaution has been taken in the preparation of this document, the publisher assumes no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein.
2022-11-30
Table of Contents
List of Figures
- 1.1. Crowd Architecture
- 1.2. Nested Crowd
- 4.1. Simple Crowd Example
- 4.2. Nested Crowd Example
Introduction
Crowd queries are used to distribute queries across multiple databases, which may reside on different machines. The corresponding query results are automatically collected from all databases and transferred back to the node, which triggered the query.
This book will explain the main concept of crowd queries.
1. Architecture
Crowd queries are exclusively executed on public databases (which require Transbase Service) and distributed to all connected databases, which can either be public or private (Transbase Edge) databases. The public database on which crowd queries are started is called crowd master and all databases which are configured to respond to the crowd queries are called crowd members (Figure Crowd Architecture).
Figure 1.1. Crowd Architecture
 |
It is possible to include a crowd query in another crowd query. If the subquery of the (outer) crowd query, which is send to the crowd members, contains another crowd query, then this (inner) subquery is again distributed to all members of all former crowd members (Figure Nested Crowd). Due to the generic design there is no limit for the nesting depth.
Figure 1.2. Nested Crowd
 |
Note that all nodes except the leafs of a nested crowd must be public databases.
2. Procedure
This chapter describes the necessary steps for the execution of crowd queries:
Configure a database as a crowd member
Make data accessible for crowd queries
Establish a connection from a crowd member to the crowd master
Execute a crowd query on the crowd master
2.1. Configure a database as a crowd member
Databases can be configured as crowd members by setting the database option crowd_master.
admin > ALTER DATABASE db > SET crowd_master='//www.transaction.de:2024/crowd_master?crowd=my_crowd';
The value of this option contains the connection string which points to the crowd master and the name of the crowd, which can be chosen arbitrarily.
2.2. Make data accessible for crowd queries
As crowd queries do not need to log in on the crowd member database and the crowd member has no influence on the query and which data it requests, the access must be restricted by privileges.
All crowd queries are executed by user crowd. This 'virtual' user (it is not possible to log in as user crowd) is automatically installed when the database is being created. By default, user crowd has no privileges on user tables and therefore all data is protected from remote access.
To permit crowd queries access to data, a common user has to grant privileges on database objects to user crowd:
db > GRANT SELECT ON x TO crowd;
2.3. Establish a connection from a crowd member to the crowd master
By switching the database property crowd_connect to TRUE or FALSE, crowd members connect or disconnect from their crowd master.
db > ALTER DATABASE SET crowd_connect=TRUE;
The connection is always established through the crowd member.
With function crowd_status(), the status (active or inactive) of the crowd service can be checked:
db > SELECT crowd_status();
If the function returns active, then the database is currently connected to the crowd master. If the function returns inactive, then there is no active connection between the database and the crowd master at the moment, but the database tries to connect every 10 seconds until the database property crowd_connect is set to FALSE or the database is shutdown. If the database is booted again, the service is started automatically, if the database property crowd_connect has the value TRUE.
2.4. Execute a crowd query on the crowd master
Once the crowd members are connected, an application, which is connected to the crowd master, can execute crowd queries. These crowd queries are common queries with one or more CrowdExpressions in their FROM clause. Please consider that these expressions have one additional (hidden) field in their result records: crowd_members.
db > SELECT s.crowd_members, COUNT(*), MAX(s.v) FROM CROWD (my_crowd)
RETURN AFTER 60 SECONDS OR 1000 MEMBERS
(SELECT date, value FROM sensors WHERE value > 99)
s
(d date, v integer)

| crowd_members delivers the total amount of connected databases, which returned a complete result. In case of a nested crowd query crowd_members delivers the total amount of crowd members on the highest crowd level. |
| identifies the crowd. The subquery is only distributed to databases, whose crowd name corresponds to this identifier. Crowd members specify the crowd, to which they connect to, through the database property crowd_master in the catalog table sysdatabase. Note that this crowd identifier can be named arbitrarily. |
| the first result record will be delivered after the time window has expired or, if specified, after the desired number of crowd members have returned a complete result. If the time window expires without a member delivering a complete result, an empty result set is delivered as the overall result. In case of a nested crowd query the time window of the inner query should be choosen smaller than the time window of the outer query. |
| is the subquery which is distributed to all connected crowd members. |
| the correlation identifier for this crowd expression. |
| Since the subquery is not beeing compiled on this level, the compiler needs to know, how the result records look like. Therefore the user has to specify each data field by an arbitrary name and by its datatype. |
3. Troubleshooting
Whenever a crowd member cannot evaluate a query successfully (e.g. query is erroneous or a runtime problem occurs), this error is not directly delivered to the crowd master. Instead a mechanism to grap occurred errors is provided, as seen below.
In the first case (erroneous query), many or all crowd members will have a problem, thus the value of crowd_members will be very low.
If this is observed or (generally speaking) if there are doubts on the quality of a result, the crowd master can access all errors (from all crowd members) of his last crowd query with the following statement:
db > SELECT crowd_member
| crowd_member is the UUID of database, which caused the error. |
| crowd_level is the nested level where the error occurred. Level zero corresponds to the database, where the crowd query was executed (crowd master), level one corrresponds to its members and so on. |
| crowd_errorcode contains the Transbase error code. |
| crowd_errortext contains the corresponding error message. |
Note that this statement only returns errors of the previously executed query for this connection. If someone disconnects from the database and reconnects again, this statement does not return errors anymore.
4. Examples
4.1. Simple Crowd
This example shows the setup of a Transbase Crowd containing two crowd members (one public and one private database). The public database is hosted on the same Transbase service (listening on //localhost:2024) as the crowd master database, which is used for execution of the crowd queries.
Figure 4.1. Simple Crowd Example
 |
First you have to start the Transbase service:
# $TRANSBASE/bin/transbase start
Then connect to the repository database and create the crowd master and the public member database:
# $TRANSBASE/bin/tbi "///admin?sslverifyca=false" Login: [tbadmin] Password: admin > create database crowd_master set encryption=none; admin > create database crowd_member_public set encryption=none; admin > quit
Next, you log in to the previously created member database, create the database schema and connect to the crowd master.
# $TRANSBASE/bin/tbi "///crowd_member_public?sslverifyca=false" Login: [tbadmin] Password: crowd_member_public > set autocommit on; crowd_member_public > create table x (a integer); crowd_member_public > grant select on x to crowd; crowd_member_public > insert into x values (1); crowd_member_public > alter database > set crowd_master='//localhost:2024/crowd_master?sslverifyca=false&crowd=my_crowd'; crowd_member_public > alter database set crowd_connect=true; crowd_member_public > select crowd_status(); crowd_member_public > quit
To create and setup the private member database, please execute the following commands in another terminal. It is important to keep the connection to the private database alive, because otherwise the database would be shutdown (during the disconnect) and the crowd service would stop.
# $TRANSBASE/bin/tbi "file://crowd_member_private" Login: [tbadmin] Password: crowd_member_private > set autocommit on; crowd_member_private > create table x (a integer); crowd_member_private > grant select on x to crowd; crowd_member_private > insert into x values (2); crowd_member_private > alter database > set crowd_master='//localhost:2024/crowd_master?sslverifyca=false&crowd=my_crowd'; crowd_member_private > alter database set crowd_connect=true; crowd_member_private > select crowd_status();
Switch back to the previous terminal and connect to the crowd master database, where you can now execute the crowd queries.
# $TRANSBASE/bin/tbi "///crowd_master?sslverifyca=false" Login: [tbadmin] Password: crowd_master > select crowd_members, sum(c.d) from crowd (my_crowd) > return after 5 seconds or 2 members (select a from x) c (d integer); crowd_master > quit
Only the expression (select a from x) is sent to the two crowd members. The aggregation function sum(c.d) is calculated on the crowd master database.
4.2. Nested Crowd
A typical application of the crowd concept is to collect values of very many crowd members and to perform some kind of aggregation in the master.
The crowd concept allows to handle very big numbers of crowd members by building an aggregation hierarchy. For example, for handling one million crowd members one can arrange 1000 crowd masters (each handling 1000 crowd members) and place one crowd master in an additional level which handles the intermediate masters as crowd members.
Starting from the previous example, we will add one crowd level by changing the crowd master of one of the crowd member databases to use the other one.
Figure 4.2. Nested Crowd Example
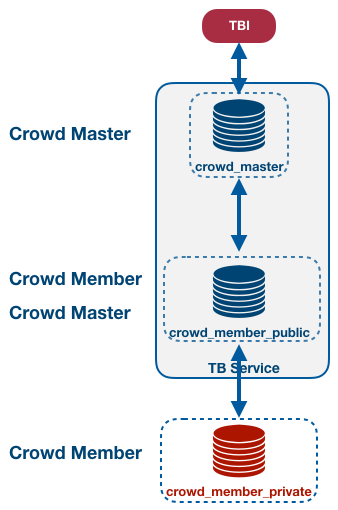
To set up the crowd as shown in figure Nested Crowd Example, connect to the private database (or switch to the other terminal, if you have not disconnected yet) and alter its crowd master:
# $TRANSBASE/bin/tbi "file://crowd_member_private" Login: [tbadmin] Password: crowd_member_private > set autocommit on; crowd_member_private > alter database set crowd_connect=false; crowd_member_private > alter database > set crowd_master='//localhost:2024/crowd_member_public?sslverifyca=false&crowd=my_inner_crowd'; crowd_member_private > alter database set crowd_connect=true; crowd_member_private > select crowd_status();
Database crowd_member_public is now a crowd member of database crowd_master as well as the crowd master of database crowd_member_private.
Switch to another terminal and connect to the crowd master database to execute the following cascading crowd query:
# $TRANSBASE/bin/tbi "///crowd_master?sslverifyca=false"
Login: [tbadmin]
Password:
crowd_master > select c.d from crowd (my_crowd) return after 5 seconds or 1 members
(
select e.f+x.a from crowd (my_inner_crowd) return after 3 seconds or 1 members
(
select a from x
) e (f integer), x
) c (d integer);The outermost expression (select c.d from crowd ... c (d integer)) is evaluated on the crowd master (crowd level 0)).
Expression (select e.f+x.a from crowd ... e (f integer), x) is evaluated on database crowd_member_public (crowd level 1).
And the innermost expression (select a from x) is evaluated on database crowd_member_private (crowd level 2).
4.3. Troubleshooting
To simulate an error we change the innermost subquery of the previous cascading crowd query from (select a from x) to (select b from x). This change should lead to a compile error on the highest crowd level.
When the query is executed again, no result records are returned. The errors can be retrieved by executing the following statement:
crowd_master > select * from lastcrowderrors;
crowd_member BA1017FF-3F8A-4F48-BAA8-27E5A6DD431E
crowd_level 2
crowd_errorcode 9069
crowd_errortext compile error: field ''b'' not resolvable, block 1, depth 1: