Transbase is a multi-user client-server distributed database system.
Transbase consists of database servers and database client software.
The term ''distributed'' means that applications can access more than one
database within a session.
These databases may be managed by different services on different hosts.
Transbase thus is called a distributed
system because it provides distributed
transactions and distributed queries. Data consistency and transaction
consistency is provided, even in the case of distributed access and
multiple updates.
Transbase provides for data security by a clean implementation
of transactions both in local and distributed operation.
To guarantee data consistency, Transbase employs locks on database
objects which are to be shared between concurrent transactions.
Deadlocks are detected and broken by Transbase, both in local and
distributed operation.
Indefinite delay is prevented by a timeout
mechanism which is of course user-definable.
Apart from that queries can internally refer to items in other databases even when managed by different servers.
Furthermore, distributed queries are supported. Details are
explained in a separate section below.
3.1. Transbase Service Architecture
A Transbase database service is contained in a single process
that is usually installed as a service process providing its services over TCP/IP connections.
Embedded servers are completely incorporated into the client process.
3.1.1. The Service Process
The Transbase software architecture is shown in the following picture.
When an application connects to the database D managed by a service S,
Transbase creates a dedicated service thread (Cl-S) for each client connection
to one of its associated databases.
A Transbase service can manage multiple Transbase databases.
A special database with the name admin is created automatically by the server.
This database can be addressed to do all database administration
and to get information about the databases under control of this server.
- Database Cache Memories
For each database that is booted and thus accessible the Transbase maintains a memory area
that serves as a database cache and enables the coordination of all activities on this database.
The size and configuration of this memory area can be specified when the database is created
and also be adjusted later.
Multiple clients can access a database at the same time. All service threads working for these clients
coordinate their activities with the help of the shared memory aera and a number of semaphores to allow quasi parallel
access to the database.
All applications use one of the Transbase client libraries implementing the proprietary
client-server communication protocol to communicate with the Transbase servers
over a TCP/IP connection.
This protocol is implemented in the native TCI (Transbase Call Interface) dynamic library
or the JDBC driver (tbjdbc.jar).
When an application CONNECTs to the database D managed by a server S, its client software ( JDBC or TCI )
sends a message to the server S using its host identification and port where the server process is listening.
The Transbase process creates a dedicated thread for each client connection
to one of its associated databases.
3.1.1.1. Configuration of Database Buffers
It is advantageous to partition the database buffer into several
partitions instead of specifying a single database buffer.
For example, the default configuration is 8 shared memories with
64 MB each. With this configuration, up to 8 service threads then can access
data lying in different cache portions simultaneously without
synchronization and mutual exclusion.
If there would be only a single shared memory with 512MB,
all threads would have to synchronize on this single shared memory which might lead to performance bottlenecks,
especially when multiple CPU cores are available.
As part of the transbase service a main memory region inside this process
exists that is shared among all workerthreads which concurrently
service clients requests on the same database.
The shared memories are created when the database is created or booted.
They are deleted when the database is deleted or shutdown.
3.1.2. Client Contexts and Service Threads
Each active client connection on a database corresponds to a Client Context (CC)
maintained by the Transbase service that runs this database.
Whenever there is activity on such a connection a dedicated service thread inside the Transbase Service
is dealing with this request.
This thread communicates with the client and
processes the client's request. It may create/use other threads as needed
or advantageous for the processing of this request.
The service thread remains dedicated to the client as long as there is an active transaction to be completed.
The degree of parallel processing can be controlled for each database
by specification of number of concurrent connections permitted.
3.2. Transbase Services on the Network
A Transbase Service manages a set of associated databases.
The Server offers its service through the TCP/IP network protocol
and is thus identified by the name of the host it is running on and the TCP/IP port it uses.
3.2.1. Runtime Environment
All Transbase service processes need appropriate definitions for the following locations and parameters:
TRANSBASE
references the base directory of this installation.
The configuration file transbase.ini is located in this directory.
It contains at least one section named [Transbase] for the standard configuration of Transbase.
Other configurations/sections with user-defined names may be added at need.
All of the following other locations and parameters are defined in the appropriate section of this file.
Since the TRANSBASE/bin directory
is the location for the Transbase operators (e.g. tbi),
it is recommended to include this path in the PATH environment variable.
TRANSBASE_RW
references the base directory for all files of this server installation that are not read only.
If the TRANSBASE directory is read-only, TRANSBASE_RW should be defined.
The file dblist.ini which contains the list of all databases managed by a Transbase service
is located in this directory.
DATABASE_HOME:
The default directory for databases. Defaults to
TRANSBASE_RW/databases.
JRE_HOME
Directory where the Java runtime is looked for.
This is only relevant for Java-enabled servers that execute Stored Procedures or User-defined Functions written in Java.
TMPDIR
A directory for temporary files.
Defaults to TRANSBASE_RW/tmp.
TRANSBASE_PORT
The port for the database service. Defaults to
2024.
Please refer to the Transbase Service Guide
for a description how these parameters can be configured properly.
3.2.2. Server Administration
Once installed the Transbase server itself requires very little attention.
Most configuration is done at the database level when the required database is created.
The following commands usually executed from the installation directory of the server
are sufficient to administer the database server.
Table 3.1. Server Commands
transbase install | Installs the database service |
transbase remove | Removes the database service |
transbase start | Starts the database service |
transbase stop | Stops the database service |
transbase query | Retrieves info about the database service |
For debugging purposes Transbase can also be started as a an ordinary console application.
transbase noservice <parameters>
3.2.3. The Databases File dblist.ini
A file dblist.ini located in the TRANSBASE_RW directory contains an
internal description of all databases managed by this server.
This file is automatically updated via administration operations.
Although it may be inspected and even modified
manually by the database administrator it is not recommended.
This situation may be compared to the ''/etc/passwd'' file of UNIX
systems which is updated automatically by tools (e.g. adduser)
or may be updated manually by the super user.
![[Note]](assets/images/note.svg) | Note |
|---|
Each database server must have its own incarnation of this file.
It must not be shared by different servers, e.g. via NFS.
|
3.2.4. The Repository Database admin
Databases can only be administrated via SQL like commands on the repository database
admin.
This special database is automatically installed and managed by the Transbase service.
See the TB/SQL-Manual
for the details of administration commands.
When a Transbase server is started an administration database called
admin is created automatically.
All database administration on this server is performed by connecting to the admin database
with any suitable Transbase frontend or application. On this admin database, however, only
database administration for this server can be performed.
With the following SQL command a new database is created:
create database <dbname>
and with the command following command the database is deleted.
drop database <dbname>
The admin database may also be used to change database parameters after database creation.
For some changes it may be necessary to shut down the database concerned.
3.2.4.1. Boot and Shutdown of a Database
After creation of a database, it is automatically booted.
A database can be booted with the following command on the admin database:
boot database <dbname>
A specific database db can be shut down with the following command at the admin database:
shutdown database <dbname>
This requires that no service threads are operating on the
database.
Booting essentially instantiates the database cache ( shared memory )
and its associated semaphores.
Associated with the shared memory region for a database is a
set of semaphores which are used by the service threads to coordinate their operations
on the database concerned.
Some database parameters con only be changed while the database
is not booted because some runtime structured must be rearranged.
Note that no explicit database shutdown is necessary before
machine shutdown, because a database shutdown
does not write any file to disk. If the machine is shutdown or
crashes and there are active processes on databases, then all
active transactions are aborted automatically and their changes are undone.
This means that with the next reboot of the database, all data is in the
most recent and consistent state.
Note that shared memory regions even exist when no application
programs are currently connected to a database.
In this situation the shared memory region may be swapped out
on secondary memory and thus does not require costly main memory space.
A daemon process/service process named Transbase running some transbase.exe
runs permantently and provides its services through a dedicated TCP/IP port.
If such service is requested by an application program (CONNECT request),
a dedicated thread is created to serve the application program's commands.
Each database client can optionally incorporate an embedded Transbase.
This enables the client software to manage private databases
that are completely controlled by the application process.
Embedded database servers are completely maintenance free.
As a consequence there is no server directory. No dblist.ini files or admin databases are needed.
Private databases are simply created at first access.
All creation parameters are specified in the connection string as properties.
They are ignored when the specified database already exists.
The database name is specified as a valid file specification, i.e. a valid pathname for the database directory.
[tbi]
co file://mydb?blocksize=64k tbadmin ''
Private databases are deleted by simply deleting the database directory in the file system.
Transbase databases are autonomous.
By autonomy we understand that each database can be run independently
of others.
Especially, each database has its own set of tables, its own name space,
and its own user community, and, of course, its own files and directories.
Transbase databases are concurrently accessible by local or remote
clients which may be located on heterogeneous machines or even
systems. Transbase uses TCP/IP communication software for remote and local
access.
Databases are named by a logical name which is unique on the local host.
When a database is accessed from a remote client, it is identified
by the hostname of the database server and the unique local name.
An application has to CONNECT to databases it wants to access;
a connection is simply a communication link to a database server.
After connection, the application program (or the user, resp.)
has to be authorized before the first statement is accepted.
Transbase employs the underlying file system to store and retrieve data from disk.
Therefore, a database consists of files. In general, several files are used to store the data from the database.
A database is identified by a unique logical name which is chosen by the database administrator at creation time.
The mapping between this logical name and the path name of the database directory is defined in the file dblist.ini
(see below).
If a database is to be accessed remotely, the database is identified by the pair (logical database name, server ).
The server is identified by the host and port where it offers its service.
4.1.1. The Database Directory
Each database has its own database directory. The path name of the database
directory is chosen at creation time and is denoted in dblist.ini.
This database directory contains at least a database
description file named dbconf.ini.
This file contains the basic configuration of the database in concern.
By default, all data of a database reside in files inside the database directory,
i.e. in proper subdirectories of the database directory.
At database creation time, however, other locations can be specified for different portions of the database data.
The default configration for each database contains the following subdirectories
as containers for different types of data:
disks
Permanent data is stored in the logical disks container. This
container contains 1 or more disk files.
These diskfiles need not reside inside the same directory (but they do
by default).
Transbase names the files disk00000.000, disk00000.001, etc.
The first number is running number, the second number gives the number of
the dataspace to which the file belongs.
roms
The ROM files container is explained in the Transbase Publishing Guide.
bfims
("before images") is a directory that stores data needed guarantee transactional integrity
and to recover the database data after a system crash.
Transbase supports two different logging strategies:
'before image logging' and
'delta logging'
Regardless of the chosen method the information needed to rollback transactions is stored in this subdirectory.
scratch
is a directory where temporary files are
created as needed (intermediate results, sorting, etc.) and destroyed
at the end of transactions.
trace
is a directory where trace output is stored by default.
4.1.2. Database Size and Database Extension
At creation time of the database, the maximum size of each
specified diskfiles must be specified. The size must be given in megabytes (MB).
As the database is filled with data, the space on disk is allocated on
a demand basis, i.e. the diskfile(s) dynamically grow until their specified
maximal size is reached.
When space is needed and there are no free blocks on any diskfile, Transbase
reports an error.
At any time, the maximal database size can be extended by adding one or more additional diskfiles.
This is done by appropriate DDL commands for the extension of additionally defined dataspace.
For this purpose, the database must be shut down.
Similar to database creation, each diskfile to be added can be specified
by its maximal size and its placement on disk.
The diskfile size can be limited by the maximum file size the operating system can handle.
Note that the first diskfile at database creation time seems to be considerably
larger as displayed by the operating system. The reason is that it contains all
system tables with their initial data. Another effect is that some database
blocks are written at predefined addresses inside the first diskfile and leave
some unallocated blocks which later on are used for user data.
4.1.3. Database Configuration
All relevant configuration parameters of a database can be retrieved from the
sysdatabases
table on the admin database or from the sysdatabase
table on the database in question.
These properties match exactly with the database parameters
that can be specified in the Create Database Statement
and are described in the Transbase Administration Guide.
Table 4.1. Structure of sysdatabase
| Field | Explanation |
|---|
| database_name | The name of the database concerned. |
|---|
| property | The database property or database configuration parameter. |
|---|
| value | The current value of this property for the specified database. |
|---|
| unit | The unit in which the current value is specified where this applies. |
|---|
| datatype | The data type of the property. |
|---|
| comment | Gives useful information on this property.
Mostly the collection of possible values and the default value. |
|---|
The same kind of information is provided for all configuration parameters that apply to database sessions,
i.e. are characteristics of an individual connection to a database.
They can be configured either as properties supplied in the connection string or as arguments to the
alter session command. As soon as a session is established they can be retrieved from the
syssession table.
Data spaces provide a linkage between the physical structure of the database,
i.e. its data files and their location, and its logical structure represented
by the database objects accessible to applications, i.e. tables, views, indexes etc..
Data spaces are collections of disk files and each disk file belongs to a data space.
The database administrator can control the physical properties of a database storage by
appropriate definition of the size and location of the disk files.
With the specification of the dataspaces where tables and other database objects are stored
the performance of accessing these objects can be fine tuned.
By default only a single data space exists with the name dspace0
and all database objects and in particular all system objects are stored in it.
For the definition of dataspaces see the Create Dataspace Statement
in the Transbase SQL Reference Manual.
Dataspaces can be
See the Alter Dataspace Statement for a detailed description.
For an example of the definition of DB objects in a dataspace
see the Create Table Statement.
The can also be moved to other dataspaces with an
Alter Table Move Statement.
Dataspaces can be published separately and therefore increase the flexibility in this process.
See the Transbase Publication Manual for a detail description of this process.
The access to Transbase databases is controlled by the definition of database users
(sometimes also referred to as logins).
These logins are password protected and the passwords are transmitted from client
to server in encrypted form only.
After the creation of a database two special users with a fixed user id are defined by default:
public
The user public has two special roles in Transbase databases.
When granting privileges to other users public serves as a reference to all users.
This differs from naming all user explicitly as it even refers to users not defined yet.
The public schema is the default schema for objects migrated from earlier versions of
Transbase and can be used as the default schema for objects created without schema specification.
See Schema Search Path
tbadmin
Upon creation of a database a database administrator (DBA) is automatically installed as user
with the user name tbadmin or TBADMIN and an empty password.
It is strongly recommended to change the DBA password immediately after creation.
(See AlterPasswordStatement in TB/SQL-Manual)
This user has user class dba and therefore can do anything on the database.
Data privacy is established by granting privileges on database
objects to users.
A database administrator is introduced as the owner
of a database. He grants access privileges to users.
Users have to login into a database by supplying their
user name and a password which is checked by Transbase.
To establish data privacy in a Transbase database, each user
(or application program resp.) has to login into
the database and have his authorization checked before being able
to access any table.
The authorization check is based on a user-changeable password.
Passwords are stored within the database in encrypted form
only.
Other database users can be added or deleted by the DBA only.
The database administrator is responsible for choosing a unique
user name (which may be different from the operating system user
identification) and a user class for a new user.
To protect machine resources and database objects against misuse,
Transbase applies three concepts with the notions userclass,
owner and access privilege.
Each user has a userclass which can be changed by
the DBA only.
(See Grant-Userclass-Statement,
Revoke-Userclass -Statement).
The userclass regulates the right to login,
to create objects (tables, views, indexes) and also
defines whether a user has the property of a DBA.
The following four userclasses are supported:
Table 5.1. User Classes and Access Rights
| Userclass | Access Rights |
|---|
| no access | No login. |
|---|
| access | Login right. Right to access own database objects and others depending on privileges granted. |
|---|
| resource | Login right. Right to create database objects.
Right to drop or modify own database objects
Right to access own database objects and others depending on privileges granted. |
|---|
| dba | All rights and privileges. |
|---|
5.2.1. Ownership and Access Privileges
The concept of owner is a relationship between users and objects.
Each object has a single owner. Initially this is the user who created the object.
When a user is deleted, all objects owned by this user are transferred to the user
with the userid 1 named tbadmin or TBADMIN.
The owner of an object has the right to change this object or delete it.
To change a database object means to change its definition and therefore its characteristic behavior.
The right to change the content of an object is controlled by privileges.
The creator of an object initially has all access privileges in grantable form.
The concept of access privileges regulates the rights to inspect or modify the data that are stored in or accessible
through a database object.
For tables and views these are the rights to
select, insert, update, delete records.
Select-, insert-, delete privileges are specified on table
granularity, update privileges are specified
on field granularity.
Each access privilege on a table for a user is either
grantable or not grantable.
If it is grantable, the user is permitted to forward the
privilege to other users (again in grantable or not-grantable form).
All system tables are owned by the database administrator.
Other users have select privilege only.
![[Caution]](assets/images/caution.svg) | Caution |
|---|
Note that a database administrator can modify the contents of any table regardless of privileges.
In particular (s)he can even manipulate the contents of the system tables directly
(using DML commands InsertStatements,
UpdateStatements, or DeleteStatements)
but this may have disastrous effects and is strongly discouraged.
|
The concept of usage privileges regulates the right to call user defined functions and stored procedures.
The user defined functions installed by default in a new database are usable by public and thus by all users.
Schemas are a concept to partition the namespaces for database object.
Each database object is identified by a combination of its schema and its name.
The name of a database object only needs to be unique within the schema it belongs to.
In the case of Transbase this is done based on database users.
This means each user intrinsicly has an associated schema and each schema in turn is tied to a user login.
As a consequence no commands are necessary to create or drop schemas.
![[Tip]](assets/images/tip.svg) | Tip |
|---|
This allows the creation of identical database objects not only with identical names,
but identical structures for each user. This may be very practical for some types of applications.
|
Transbase provides a variety of different table types.
- Clustered Tables
This is the standard table type for Transbase.
The records in these tables are stored in B-Trees (standard B-Tress or HyperCube Trees)
ordered according to their primary key definition.
- Flat Tables
are defined without primary key.
The data are simply stored in input order.
This makes insertion operations faster,
but retrieval operations may in most cases require a complete table scan and thus be very slow.
These tables can be restricted in size with the effect that the oldest records are discarded when new ones are inserted.
- File Tables
These are simply references to external files that need to adhere to certain formats with a tabular structure.
The field definitions of such a table must be compatible with the contents of the referenced file.
They can be referenced in SQL SELECT statements like any other table.
File tables are primarily designed as an advanced instrument for bulk loading data into Transbase
and applying arbitrary SQL transformations at the same time.
For details see the CreateTableStatement
in the Transbase SQL Reference
5.3.1.1. Internal Keys (IKs)
Transbase tables can be created with or without an Internal Key (IK).
An IK is an additional 64-bit integer field that is added to each record internally.
IKs are not shown by default. They do not appear on a query using the * symbol as the select list.
They can however be selected with the syskey keyword.
select syskey, * from mytable
IKs are used internally as row identifiers, e.g. for referencing records in the base relation after accessing secondary indexes.
Alternatively Transbase can use the primary key access path.
In this case the base table's primary key is stored in all index records for referencing the base relation.
Depending on how extensive the primary key is, Transbase will automatically decide at table creation time
whether to create a table WITH or WITHOUT IKACCESS.
This guarantees optimal space efficiency.
If the primary key occupies no more that the IK, then the table is created WITHOUT IKACCESS.
Else an IK access path is added by default.
5.3.1.2. Primary Keys and Primary Storage
Clustered tables are the usual type of tables used with Transbase.
Clustered storage is provided according to a primary key definition.
This provides fast access to single records with a certain value of the primary key fields
or to records whose primary keys are in a specified interval.
As primary key provides some ordering on the primary key field(s)
joins with other tables where these primary key fields occur in the join criteria can be performed efficiently.
5.3.1.2.1.1. Clustered Storage
Clustered Storage means that records that have the same values according to the corresponding key
are stored in a cluster, i.e. close together.
This is of major importance for large database tables in order to reduce the physical IO required to
retrieve certain records.
Constraints are conditions defined to ensure the consistency of data in the database.
The verification of constraints causes some overhead on the manipulation of data
but they help to ensure the consistency of data regardless of the correct functioning of applications modifying the data.
Constraints can be embedded into table definitions
or be added or removed later with an alter table statement.
There are two basic types of constraints.
Check Constraints
specify conditions that the fields of each record in atable need to fulfil.
They are verfied whenever a record is inserted or modified.
| Tip |
|---|
Constraints that refer to a single field only can be embedded in a domain,
in particular when they appear in more than one table.
|
Referential Constraints
specify that a field value or a certain combination of field values essentially define a reference
to some record in another table.
The referenced record contains some data applying to the referencing record
that shall not be stored redundantly in the record itself.
This is often referred to as a foreign key relationship.
The fields in the referenced table must either form the primary key of the table
or constitute a unique key supported by a unique index.
The fields in the referencing table may eventually be null, if the referenced entity may be unknown.
For details refer to the foreign key definition in the
Transbase SQL Guide.
Transbase does not feature Uniqueness Constraints. These are handled by different constructs.
The uniqueness of the primary key fields of a table is such an essential feature
that it is incorporated into the table definition for a Transbase table.
In order to change this a table essentially needs to
be dropped and recreated with adapted primary key specifications.
Unique Indexes:
As the efficient enforcement of such a unique constraint in almost all cases requires a secondary index
on the field or the combination of fields involved, Transbase requires the specification of such a restriction
with the CreateIndexStatement.
Transbase features different types of indexes for different purposes:
5.3.3.1. Standard Indexes
Standard indexes provide quick access to records with specific values for the indexed fields
or to records whose values are in specified intervals.
They can provide support for join operations as they provide access to records in a sorted
order according to the indexed fields.
The ordering of values in the index is in hierarchical form
according to the sequence of the specified key fields.
See the create index statement for details.
Bitmap indexes are preferably used for
non-selective columns having few different values (e.g. classifications).
Bitmap indexes are innately very space efficient.
With their additional compression in average they occupy less than on bit per index row.
A bitmap index can be created on any base table (B-Tree or Flat) having a single INTEGER
or BIGINT field as
primary key or an IKACCESS path.
Bitmap processing allows inexpensive calculation of logical combinations (AND/ OR/ NOT)
of restrictions on multiple non-selective fields using bitmap intersection and unification.
See the create bitmap index statement for details.
5.3.3.4. Fulltext Indexes:
Fulltext indexes can be defined on a single textual fields including CLOB fields.
Thus fulltext indexes are a prerequisite for efficient data retrieval in large text archives.
A fulltext index is the prerequisite for fulltext search on the specified field (Fulltext-Predicate).
This is essentially a search for the occurence of specified words in a text.
It is the only index that can be used to index CLOB fields where it unfolds its special power.
A fulltext index splits up the text in a field in words and records the occurrence of words in the specified field of each record indexed.
There are two variants of fulltext indexes:
Word Indexes only record the occurrence of words in the specified field of a record.
Thus the fulltext search can only refer to the occurrence or non-occurence of specified words in the specified field of a record.
Positional Indexes record the occurences and positions of words in the specified field of a record.
Thus search predicates can refer to combinations of specified words occurring in the text in the predefined order.
Even more general positional indexes allow the specification of words occurring in the text in a predefined order with
predefined distances regardless of the words in between. We call this type of search a phrase search.
See the create fulltext index statement for details.
A trigger is a user defined sequence of SQL modification statements or CallStatements
which is automatically executed when an INSERT, UPDATE or DELETE statement is executed on the table the trigger is defined on.
Different types of triggers can be defined on the DML operations mentioned above.
They can be characterized by different criteria.
First they are defined to be evaluated on one of the operations INSERT, UPDATE or DELETE.
Triggers can be classified by the granularity of their activation:
Statement Triggers are evaluated once for each statement executed that is of the kind the trigger is specified for.
Row Triggers are activated for each row being processed in one of the above operations.
They can refer to the values of the row being processed.
Depending on the nature of the operation the SQL statements in the trigger can refer to the old, new or both values
of each field of the record being processed.
Triggers can also be distinguished by the sequence the complete operation is performed:
Before Triggers are evaluated before the statement is evaluated or the record to be processed is inserted, updated or deleted.
After Triggers are evaluated after the statement is evaluated or the record to be processed is inserted, updated or deleted.
Only after triggers on rows can refer to field values generated by the database.
When the evaluation of trigger leads to an exception the entire statement will be aborted and no modification occurs.
The modification of records in a table that is the target of referential constraints
can cause modifcations of the content of the referencing tables. The referencing fields may be set to NULL or the referencing
record may be deleted if the references are no longer valid. This can be interpreted as an implicit trigger specification
that is called a referential trigger.
With this definition we can denote the order of trigger execution as follows:
(1) Before-StatementTriggers
(2) Before-Row Triggers
(3) Reference Triggers
(4) After-Row Triggers
(5) After-Statement Triggers
Note that the firing of a trigger may cause the firing of other triggers when the trigger performs modifications of data itself.
While triggers often perform data modifications on other tables
it is strongly discouraged that triggers perform additional inserts, updates or deletes on the table they are defined on.
The results may in some cases be unpredictable.
See the create trigger statement for details.
Views are essentially virtual tables specified using a SELECT statement ()and eventually some additional field aliases).
They contain no data but the data are computed on demand with the defining SELECT statement.
Views may in most places be treated like real tables that are often called base tables for distinction.
Therefore views are listed in the catalog table systable and their fields are also listed in the syscolumn table.
View can also be subject to DML operations INSERT, UPDATE or DELETE and the same set of privileges as defined for
base tables also applies to views.
In order to perform these operations the view also needs to be updatable.
This is the case when the defining SELECT statement is updatable.
So views can be regarded as predefined queries or query blocks that simplify data retrieval.
This is useful in normalized database schemata where views help to rejoin the data distributed across various tables.
They can also be employed to provide individual subsets of the data to different users.
| Tip |
|---|
The keyword USER can be very helpful to provide access to individual tables when used as a schema qualifier or
to individual subsets of the data when they are tagged with some property the user logged-in can be associated with. |
For details see the CreateViewStatement
in the Transbase SQL Reference
A domain is a named type, optionally with default value and integrity constraints.
Domains can be used in CreateTableStatements (for type specifications of fields)
and as target types in CAST expressions.
When a domain is used in a CAST expression the cast value must fulfill all domain constraints.
When a domain is used in as a type specification of a field the domain-specific default maybe
overridden in the field definition.
When the default specification in the field definition is dropped, the domain default is valid again.
Additional constraints may be defined on the field but the constraints specified in the domain are enforced in any case.
CREATE DOMAIN latitude AS DOUBLE DEFAULT 0
CONSTRAINT c_latitude CHECK ( VALUE between -90.0 and 90.0 ),
CREATE DOMAIN longitude DOUBLE DEFAULT 0
CONSTRAINT c_longitude CHECK ( VALUE between -180.0 and l80 ),
For details see the CreateDomainStatement
in the Transbase SQL Reference
Sequences are generators for 4-byte integers (datatype BIGINT in Transbase).
They are often used to generate unique keys for tables.
In a more application centered perspective
they are often used to generate unique ids for objects persisted in the database.
Sequences are guaranteed to produce a new value on each call to the nextval() function.
The value returned is unique regardless of the function being called from different transactions
possibly running concurrently on different threads.
The uniqueness is not even in question when some of the transactions involved will be rolled back.
For details see the CreateSequenceStatement
in the Transbase SQL Reference
5.7. User-Defined Functions and Stored Procedures
Stored Procedures (STP) and User-Defined Functions (UDF) enable any Transbase user to extend server side functionality
by providing user-defined routines explicitly callable via SQL statements or implicitly by event driven database triggers.
User-defined functions can be provided either as a dynamicly loaded library written in C
or as class files written in Java.
Stored Procedures can currently only be written in Java and are thus only available for Java-enabled Transbase services.
As the implementation of these function/procedures and their integration into Transbase
needs some more explanation we provide a separate manual on
Stored Procedures and User-Defined Functions.
Transbase provides quite a few features that may not be available in every database
but may turn out to be quite useful for certain types of applications.
These features appear here in no particular order of importance or application area.
Distributed queries allow the combination of data from different databases in a single SQL query.
These queries can also be used to update one of the databases involved.
Transactional consistency across all participating databases is ensured automatically.
Distributed queries are executed at a single database the application is connected to.
We refer to database objects on this database as local objects.
Objects in other databases are called remote objects.
Access to remote objects ( mostly tables ) is achieved with remote references.
Table names in the FROM clause of an SQL statement can be extended by a database reference.
Syntax: table@database
The database reference in turn is either a reference to a private or public database.
Therefore it is either a database name
and a server specification with the syntax:
<tablename>@//<hostname>[:<port>]/<dbname>
or
<tablename>@<dbname>[@<hostname>][:<port>]
or a reference to a private database
with the syntax:
<tablename>@file://<databasepath>
If a query contains a foreign database reference, the database server
establishes a distributed query processing plan.
Other service threads are started at
demand at the addressed databases and deliver partial results to the main
processing service thread.
The distributed processing of the query remains transparent to the application
except the explicit formulation of the remote databases within the tablenames.
Distributed queries currently have the following restrictions:
DDL statements are restricted to local tables.
INSERT queries on remote tables are only allowed if the table has no
STATEMENT triggers (however triggers defined with the FOR EACH ROW clause are allowed).
UPDATE and DELETE statements against remote tables are possible if there are no subqueries
referring to tables which are not on the same database.
SELECT queries against one remote table are not updatable, i.e. no DELETE POSITIONED
or UPDATE POSITIONED is allowed.
Please refer to the Remote Database References section in the
Transbase SQL Reference Manual for further information.
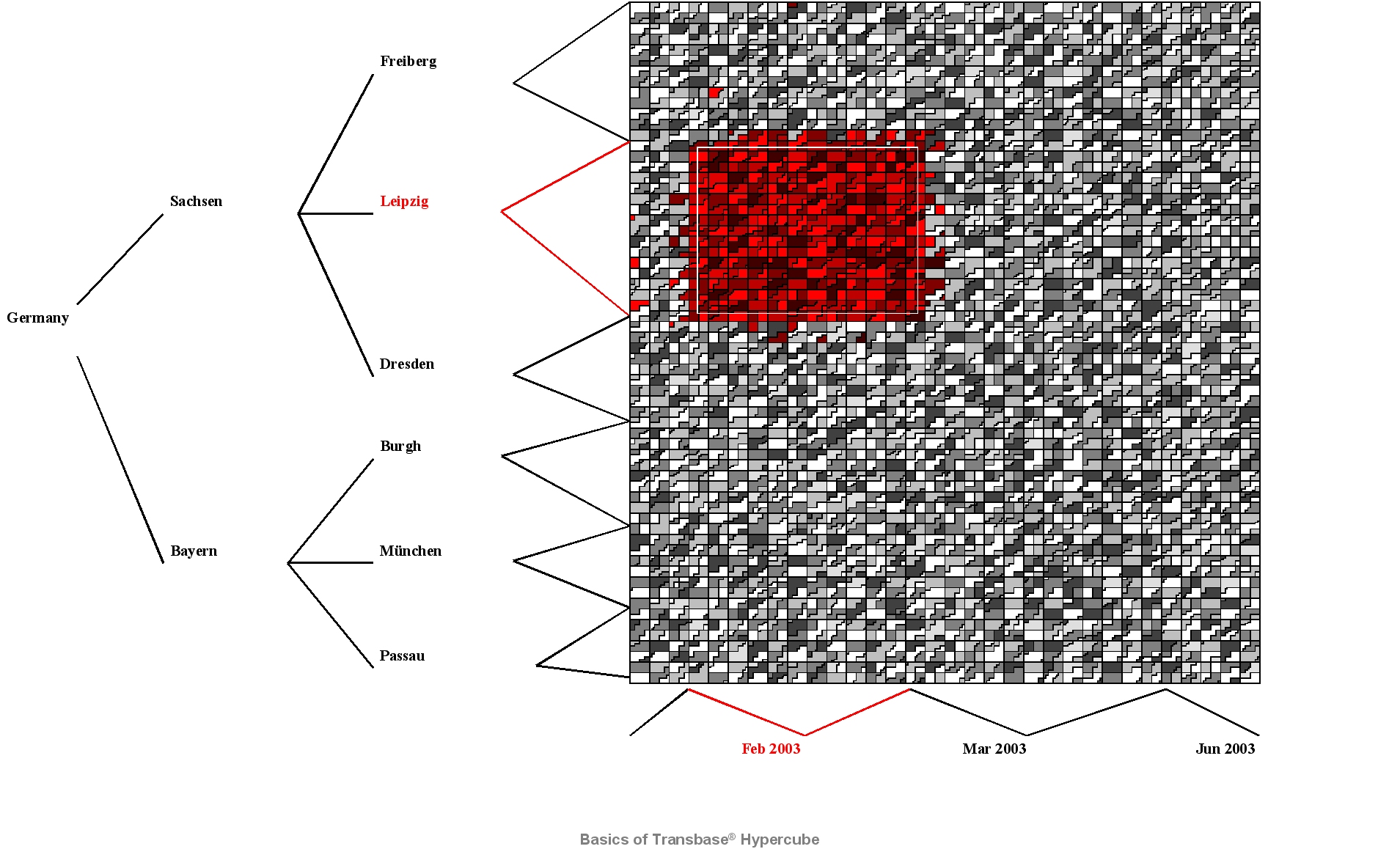
6.2. The HyperCube Technology
The HyperCube Technology is based on the UB-Tree invented by Prof. R. Bayer which is a multidiensional generalization
of the well-known B-Tree employed in many database systems.
With Transbase this technology can be used for both either as primary storage
(cmp. CREATE TABLE statement)
or for secondary indexes (cmp. cmp. CREATE INDEX statement).
The B-Tree provides a clustered storage where the clusters are stored in some linear order
based on the values of one or more key fields like e.g. in a phone book.
The Hypercube Technology provides sorted clustering with respect to several dimensions that are of equal weight.
6.2.1. Multidimensional Clustering
A UB-Tree is especially good in processing multidimensional range queries,
as it only retrieves all Z-regions that properly intersect the query box.
Consequently, it usually shows the nice behavior
that the response time of the range query processing is proportional to the result set size.
The following figure taken from a real world database illustrates this behaviour of this clustering
by showing the data read from primary storage (in redish color) to retrieve all data located in the
query rectangle specified by two range restrictions on the depicted fields.
See the HyperCubeIndexStatement for details on how to create a multidimensional index.
6.2.1.1. Hierarchical Clustering (HC)
Hierarchies play an important role in various application domains.
They are used to provide a semantic structure to data, e.g., a geographical classification of customers in a data warehouse.
As the hierarchies cover the application semantics they are used frequently by users
to specify the restrictions on the data as well as the level of aggregation.
The restrictions on the hierarchies usually result in point or range restrictions on some hierarchy levels.
The problem that arises is that these restrictions on upper hierarchy levels lead to a large set of point restrictions on the lowest level,
i.e., the level with the most detailed information.
For most access methods it would be more efficient to process one range restriction instead of a set of point restrictions.
The resulting question is how to map a point/range restriction on a higher hierarchy level to a range restriction on the lowest level?
To this end, Transbase® applies the clustering scheme for hierarchies.
A special kind of keys is used for the elements of the lowest level which reflect the hierarchy semantics,
i.e., keys which adhere to the partial order defined by the hierarchy levels.
These so-called (compound) surrogates guarantee that the keys of all elements in a sub-tree of the hierarchy
lie within a closed interval such that a key of an element not lying in the subtree is not within the interval.
We refer to this technique as hierarchy clustering (HC) from now on.
When we combine HC and multidimensional indexing on multiple hierarchy encoding as it is done in Transbase,
then we speak of multidimensional hierarchical clustering (MHC).
6.2.1.2. Multidimensional Hierarchical Clustering (MHC)
The Hypercube technology now combines these two techniques into multidimensional hierarchical clustering.
The surrogate technique is extended to provide compound surrogates for multiple dimensions.
This approach generates the full power of the HyperCube technology for data warehouse applications
and their typical query structures.
6.3. Retrieval of Database-Generated Values
When records are inserted into a table collisions with records already in the table
regarding primary key fields or fields specified as unique within indexes may arise.
Therefore the task of generating unique values for ids is often left to the database.
This can be achieved by using sequences (with their nextval() function)
as a default value for an id field
or by declaring an id field as AUTO_COMMIT field.
But then the problem arises to get hold of these database-generated values in the application program
in order to refer to them e.g. when creating other entities referring to these values.
Transbase offers a convenient solution for this problem by introducing the
INSERT statement with RETURNING clause.
INSERT INTO T(t0,t1) VALUES (123 ,'asd') RETURNING(key)
In case of an AUTO_COMMIT field being involved and only single records being inserted
the value of the new record in this field can also be retrieved with the
LAST_INSERT_ID() function.
The solution with the
INSERT RETURNING clause, however, is much more
flexible as it can also retrieve other generated values like e.g. timestamps or other derived values.
When inserting more than one record additional fields can be returned so that the generated values
can be associated with the corresponding entities.
The trace feature of Transbase is a general mechanism to log
Events occurring on the database.
For each event one line is added to a Trace-File
which holds information such as time, event, username and also
additional event-specific information.
Examples for events which can be logged are the occurrence of errors,
login attempts, the begin and end of transactions or the execution of
DDL-statements.
All server tasks working on the same database log into the same database-specific files.
7.2. Layout of the Trace File
For convenience, the layout of the database trace file is such that it can
either be used for being spooled into a database table (spool format)
or to be imported to a table calculation program (csv format).
For each event, one line (record) is appended to the trace file.
The meaning of the entries of a row are declared by the following schema of a table
where the trace file can be spooled to:
CREATE TABLE "public"."systrace" WITH IKACCESS
(
InstanceID bigint, -- instance id
ProcessID integer, -- process id
ClientIP char(*), -- IP adress of connected client
ConnectionID integer, -- sequence for session
Login char(*), -- current user name
Database char(*), -- database name, not yet used
Program char(*), -- name of calling program, not yet used
Seq bigint, -- unique identifier
CurrentTime datetime[yy:ms], -- timestamp
Class char(*), -- event class
Subclass char(*), -- event subclass
TaId integer, -- Transaction identifier
QueryId integer, -- Query identifier
StmtId integer, -- Statement identifier
Query char(*), -- SQL statement
Info2 char(*), -- more info, depending on class
Info3 char(*), -- more info, depending on class
Info4 char(*), -- more info, depending on class
Info5 char(*), -- more info, depending on class
Info6 char(*), -- more info, depending on class
Info7 char(*) -- more info, depending on class
) key is "Sequence";
7.3. Trace Event Categories
All database events, that can be logged are in one of the following categories.
Thus the trace facility can be customized according to these categories.
CONN
logs any connect, login or disconnect calls to the data-base.
In case of failed attempts the reasons for the failure
(undefined user, wrong passwd etc.) are included.
TA
logs all transaction related events triggered by Begin-, Abort- or Commit-Transaction calls to the database.
For distributed transactions, an internal Prepare-To-Commit call is logged too.
SQL
logs the execution of SQL statements.
STORE
logs the preparation of stored statements.
STAT
logs statistics at the end of statements or at the end of a session.
ERROR
logs error events that occur when processing requests.
Error events are roughly distinguished as Hard if the transaction is aborted due to this error
or Soft otherwise.
8. Transactions and Recovery
A rollback of a transaction is the event that an update transaction is not committed
and all its changes against the database are made undone.
Different circumstances may lead to the rollback of a transaction,
namely either an explicit abort call of the application or a hard runtime error
detected by the service thread such as lack of dynamic memory that causes it to perform the rollback.
In case of an unexpected software termination or a machine crash,
possibly several transactions may remain uncomitted
and must be rolled back by the database booting procedure after reboot of the machine.
The default method of Transbase to support rollback and crash recovery is called
'delta logging' (as described below).
An alternative method is called 'before image logging'
The choice is a database configuration parameter which can be altered
via an administration command (the latter requires a shutdown and reboot of the database).
Delta logging writes a sequential stream of database changes into so called 'logfiles'
which are files L0000000.act and L0000001.act and so on (each having identical size which is configurable).
The changes consist of records which describe the updates on database blocks on byte level.
At commit time, the produced logfile entries in memory are forced to their corresponding logfile.
Changed blocks may remain in the database buffer pool and will later be asynchronously written to diskfile
when the page is no longer needed.
While new logfiles L*.act are added, older logfiles eventually are deleted (based on a configurable expiration time).
After a system crash, the existing logfiles are used for two purposes:
Already committed transactions whose effects are not yet completely on diskfiles are redone
and interrupted transactions are made undone on diskfiles.
This requires reading the logfiles in both directions.
8.4. Before Image Logging
The default recovery method (as described above) is "delta logging"".
A database may be configured with an alternate recovery method "beforeimage"."
With this method, before images of changed database blocks are stored in files 'bfmxxxxx.xxx'
(bfims directory) which are private to each transaction.
An additional file bfmshare.000 which typically is very small is shared among all current transactions.
To commit a transaction, all changed blocks are forced to their places in the database files.
To roll back a transaction, the corresponding blocks are written back from the before image file
into the database diskfiles. The corresponding before image file then is deleted.
Sometimes this is deferred to avoid frequent creation and deletion,
but at least at database shutdown time all before image files are deleted.
As long as an update operation is in progress, additional files savxxxxx.xxx
may be present for the rollback of one single update operation in case of integrity violations.
The recovery method "beforeimage" is well suited for long update transactions,
especially for mass loading, index creation and database build up.
However, it performs bad for short update transactions with heavy load,
because all changed blocks are forced to the diskfiles at commit time
followed by a sync call to the (usually very large) diskfiles.
After a system crash, all committed transactions are already reflected in the diskfiles,
thus only the interupted transactions have to be rolled back by the same mechanism as described for runtime rollback.
8.5. Delta Logging Revisited
If the database is configured with the default "delta logging", it may still happen that some files 'bfmxxxxx.xxx'
appear in the bfims directory (especially for very long update transactions). This is to accelerate a runtime abort
of the long transaction by avoiding the lengthy backward read in the logfile.
9. Backup and Dump of the Database
To protect a database against loss or destruction by disk hardware failure, dump mechanisms are provided.
9.1. Discouraged: Manual Copying of Database Files
In general, a file copy operation on all database files does not produce a fileset which
represents a consistent database.
If a database is in operation (update transactions running) then a consistent backup can only be produced by a
suitable administration command.
9.2. Prerequisite: Delta Logging
Note that only delta logging (in contrast to beforeimage logging) provides the functionality for dumping the database..
For disk recovery, the database should be dumped periodically with a special administration command.
A database shutdown is not necessary for this dump.
The generated dump should be kept on a save place.
A full dump consists of all diskfiles and of some L*.act logfiles at the time of dumping.
A full dump is made by the following command:
DUMP DATABASE <db> TO DIRECTORY <dir>
This command creates a directory <dir> and stores all relevant database files into <dir>.
Relevant logfiles are stored into a subdirectory D000000.
With this dump, the database can be restored into a state as it was at the time the dump was made.
Any change on the database which is done after the dump has been produced, will of course be lost if the dump is used
to replace the database.
To refresh the dump with the most recent changes, one could either make a new Full Dump. A faster method is to complete the
dump with the most recent changes as described in the following.
Alternatively to the Full Dump an Incremental Dump method is provided. An Incremental Dump can only be done
against an already existing Full Dump.
DUMP DATABASE <db> INCREMENTAL TO DIRECTORY <dir>
This command adds logfiles of the database to the dump directory thus pushing the dump to the
current state of the database.
Performing an Incremental Dump adds one subdirectory Dxxxx (with a running number) to the main directory
which then contains all logfiles of the database which were not yet in the dump.
Incremental Dumps may be iterated many times, but restoring a database from a highly accumulated
Incremental Dump is a bit slower than restoring from a Full Dump.
If the keyword DIRECTORY is replaced by FILE,
the produced dump consists of a single file instead of a directory structure.
The INCREMENTAL variant appends to the existing file.
9.6. Restoring the Database from a Dump
There are two ways to do that:
If the directory structure of the destroyed db is intact, then in-place recovery might work.
ALTER DATABASE <db> UPDATE FROM
DUMP {{FILE {<file>|<device>}}|{DIRECTORY <dumpdir>}}
This command will use the database setting as provided in the configuration file residing in
<db>'s database directory.
If the directory structure of the destroyed db is not intact, or the database is to be recovered
to a different location, then use:
CREATE DATABASE <new_db> FROM
DUMP {{FILE {<file>|<device>}}|{DIRECTORY <dumpdir>}}
This will build a new database <new_db>, using the configuration file from
the dump.
Transbase Replication provides functionality for creating copies of databases (replicas),
which are frequently updated to ensure consistency between the original and the copies.
Replication can be used for following purposes:
load balancing: to avoid an overload on one database, requests can be distributed across a set of replicas on different computers.
The Transbase service can work as the load balancer when the replicas are organised into Grids.
accessibility: when a computer fails, another computer with a copy of the database is still reachable.
reliability: if the original database gets corrupted,
one of the corresponding replicas can replace the original database.
Transbase Replication is based on the client-server architecture.
Every replica (client) communicates with one thread of the corresponding transbase service or the origin.
A replica can also act as an origin for other replicas (cascading).
Private databases can only be replicas whereas an origin must be a public database.
Replication is based on the "delta logging" transaction recovery method (see DeltaLogging),
which writes a sequential binary stream of all database changes into logfiles.
The content of these logfiles is also streamed to the replicas, where the logentries are read and applied to the diskfiles.
If a replication service is started for a replica, which actually does not exist,
a full dump (see FullDump ) is transferred from the origin to the replica to create the initial database.
Replicas need not be connected permanently to the origin. They can disconnect at any time, leaving full functional databases.
As soon as a replica connects again, all missing logfiles are streamed to the replica and applied.
If there are no changes on the original database, there is also no network traffic to the replicas.
But whenever changes are made to the original database, all replicas get the updates immediately, i.e. after each completed transaction.
Depending on your needs, Transbase Replication can be run in several modes (asynchronous, semi-synchronous and synchronous).
In asynchronous mode the binary log is transferred to the replicas as soon as possible, but a commiting transaction on the original database does not have to wait until the replicas received the complete log. So in case of a system crash on the origin side, there is no guarantee that all data of already committed transactions has been transferred to the replicas.
In semi-synchronous mode a commiting transaction on the original database must wait until all replicas have received the entire log and written it to disk. Because of old readers on the replicas the changes are possibly not visible at this particular time. But in case of a system crash, the replicas are able to replay the full log.
Synchronous replication works like semi-synchronous replication, but as long as the log has not been replayed on a replica, no new transactions are permitted on this replica.
It is possible to run one replica in synchronous mode and another one in asynchronous mode.
10.3. Preconditions and Restrictions
Replication is possible between different types of operating systems,
e.g. the operating system hosting the original database is Linux and an associated replica runs under Windows.
But it is not possible to replicate between two machines with different byte order.
Both sides must run either on little endian machines or big endian machines.
All updates/write operations have to be made on the original database. The replicas are read-only databases.
The transbase replication service only works with delta logging and not with before image logging.
In order to do so, parameter RECOVERY_METHOD must be switched to value LOGGING and the size of the logfiles
must be set to a value > 1MB.
ALTER DATABASE db SET LOG_FILE_SIZE=1, RECOVERY_METHOD=LOGGING
Because there is only one binary delta log for an entire database, it is not possible to replicate selected dataspaces or tables.
Only the entire database can be replicated.